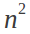Today i tested matrix multiplication using Aparapi and my 7770 card. The results are great, another 40X improvement over my quad core 960T cpu.


The interesting part is that the shape of the graphs is the same. This means that we can't change the complexity of the algorithm by using a gpu but only make it a lot run faster.
The results
and also the Java Code
import java.util.Random;
import com.amd.aparapi.Kernel;
public class MatrixMultiplication {
public static void main ( String [] arg ){
test( 500,500,500 );
test( 1000,1000,1000 );
test( 1500,1500,1500 );
test( 2000,2000,2000 );
test( 2500,2500,2500 );
}
public static void test ( int a, int b, int c ){
Random rnd = new Random();
int [] A = new int[a*b];
int [] B = new int[b*c];
for ( int i=0; i<A.length; i++ ){
A[i] = rnd.nextInt( 1000 );
}
for ( int i=0; i<B.length; i++ ){
B[i] = rnd.nextInt( 1000 );
}
long min = Integer.MAX_VALUE;
for (int i = 0; i < 2; i++) {
long start = System.currentTimeMillis();
int[] rezultat = mult(A, B, a, b, c);
long end = System.currentTimeMillis();
min = Math.min( min, end - start );
}
// printMatrix( A, a, b );
// System.out.println();
// printMatrix( B, b, c );
// System.out.println();
// printMatrix( rezultat, a, c );
System.out.println( "[" + a + "," + b +"]X[" + b + "," + c + "] " + min + " ms" );
}
public static void printMatrix( int [] m, int a, int b ){
for ( int i=0; i<a; i++ ){
for ( int j=0; j<b; j++ ){
System.out.print( m[i*b+j] + " " );
}
System.out.println();
}
}
public static int [] mult( final int [] A, final int [] B, final int a, final int b, final int c ) {
final int [] rezultat = new int [ a * c ];
Kernel kernel = new Kernel() {
@Override
public void run() {
int k = getGlobalId();
int linie = k/c;
int coloana = k%c;
for ( int i=0; i<b; i++ ){
rezultat[k] += A[ linie*b + i ] * B[ i*c + coloana ];
}
}
};
kernel.setExecutionMode( Kernel.EXECUTION_MODE.CPU );
kernel.execute( rezultat.length );
return rezultat;
}
}