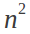The coding of the parallel version was very easy because the algorithm is data parallel by its nature, so what i have done was just to execute the 2 inner loop in a kernel N times ( N=number of nodes ).
We will compare the classical iterative version and the Aparapi OpenCL version executed on the CPU and GPU. Lets see the results.
For a graph with 1024 notes ( this algorithm has a N^3 complexity so 1024 is a pretty large number )
The first thing that i noticed is that the iterative version is very fast, in total there are 1073741824 iterations to be done and the iterative version finished in 1406 ms, this means 763685 iterations per ms. Taking into account that just starting a kernel ( without memory copy or OpenCL translation ) takes around 0.6 ms on my system i think that running a kernel for performing anything less that 500 000 will run slower that an iterative version ( this number clearly differs from one system to another, but i think is in this range ).
Because of this the speed increase for the GPU version is just 2X.
One strange thing is the very bad performance for the Aparapi CPU version, I' am not sure what is causing this, i currently assume that is has to do with the algorithm not being very cache friendly when run on the CPU.
The gap has increased to 6.6X between the iterative version and the Aparapi version.
Another speed increase of around 10x.